

TAR 2.0 and the Case for More Widespread Use of TAR Workflows
February 5, 2021
|
By:
Cut-off scores, seed sets, training rounds, confidence levels – to the inexperienced, technology assisted review (TAR) can sound like a foreign language and can seem just as daunting. Even for those legal professionals who have had experience utilizing the traditional TAR 1.0 model, the process may seem too rigid to be useful for anything other than dealing with large data volumes with pressing deadlines (such as HSR Second Requests). However, TAR 2.0 models are not limited by the inflexible workflow imposed by the traditional model and require less upfront time investment to realize substantial benefits. In fact, TAR 2.0 workflows can be extremely flexible and helpful for myriad smaller matters and non-traditional projects, including everything from an initial case assessment and key document review to internal investigations and compliance reviews.

A Brief History of TAR
To understand the various ways that TAR 2.0 can be leveraged, it will be helpful to understand the evolution of the TAR model, including typical objections and drawbacks. Frequently referred to as predictive coding, TAR 1.0 was the first iteration of these processes. It follows a more structured workflow and is what many people think of when they think of TAR. First, a small team of subject-matter experts must train the system by reviewing control and training sets, wherein they tag documents based on their experience with and knowledge of the matter. The control set provides an initial overall estimated richness metric and establishes the baseline against which the iterative training rounds are measured. Through the training rounds, the machine develops the classification model. Once the model reaches stability, scores are applied to all the documents based on the likelihood of being relevant, with higher scores indicating a higher likelihood of relevance. Using statistical measures, a cutoff point or score is determined and validated, above which the desired measure of relevant documents will be included. The remaining documents below that score are deemed not relevant and will not require any additional review.
Although the TAR 1.0 process can ultimately result in a large reduction in the number of documents requiring review, some elements of the workflow can be substantial drawbacks for certain projects. The classification model is most effectively developed from accurate and consistent coding decisions throughout the training rounds, so the team of subject-matter experts conducting the review are typically experienced attorneys who know the case well. These attorneys will likely have to review and code at least a few thousand documents, which can be expensive and time consuming. This training must also be completed before other portions of the document review, such as privilege or issue coding, can begin. Furthermore, if more documents are added to the review set after the model reaches stability (think, a refresh collection or late identified custodian) the team will need to resume the training rounds to bring the model back to stability for these newly introduced documents. For these reasons, the traditional TAR 1.0 model is somewhat inflexible and suited best for matters where the data is available upfront and not expected to change over time (i.e. no rolling collections) so that the large number of documents being excised from the more costly document review portion of the project will offset the upfront effort expended training the model.
TAR 2.0, also referred to as continuous active learning (CAL), is a newer workflow (although it has been around for a number of years now) that provides more flexibility in its processes. Using CAL, the machine also learns as the documents are being reviewed, however, the initial classification model can be built with just a handful of coded documents. This means the review can begin as soon as any data is loaded into the database, and can be done by a traditional document review team right from the outset (i.e. there is no highly specialized “training” period). As the documents are reviewed, the classification model is continuously updated as are the scores assigned to each document. Documents can be added to the dataset on a rolling basis without having to restart any portion of the project. The new documents are simply incorporated into the developing model. These differences make TAR 2.0 well suited for a wider variety of cases and workflows than the traditional TAR 1.0 model.
TAR 2.0 Workflow Examples
One of the most common TAR 2.0 workflows is a “prioritization review,” wherein the highest scoring documents are pushed to the front of the review. As the documents are reviewed the model is updated and the documents are rescored. This continuous loop allows for the most up-to-date model to identify what documents should be reviewed next, making for an efficient review process, with several benefits. The team will review the most likely relevant, and perhaps important, documents first. This can be especially helpful when there are short timeframes within which to begin producing documents. While all documents can certainly be reviewed, this workflow also provides the means to establish a cutoff point (similar to TAR 1.0) where no further review is necessary. In many cases, when the review reaches a point where few relevant documents are found, especially in comparison to the number of documents being reviewed, this point of diminishing returns signals the opportunity to cease further review. The prioritization review can also be very effective with incoming productions, allowing the system to identify the most relevant or useful documents.
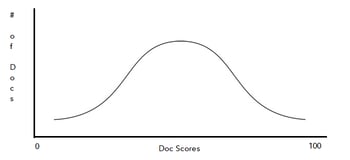
An alternative TAR 2.0 workflow is the “coverage” or “diverse” review model. In this model, rather than reviewing the highest scoring documents first, the review team focuses on the middle-scoring range documents. The point of a diverse review model is to focus on what the machine doesn’t know yet. Reviewing the middle range of documents further trains the system. In this way, a coverage TAR 2.0 review model provides the team with a wide variety of documents within the dataset. When using this workflow for reviews for productions, the goal is to end up with the documents separated between those likely relevant and those likely not relevant. This workflow is similar to the TAR 1.0 workflow as the desired outcome is to identify the relevant document set as quickly or directly as possible without reviewing all of the documents. To illustrate, a model will typically begin with a bell-shaped curve of the distribution of documents across the scoring spectrum. This workflow seeks to end with two distinct sets, where one is the relevant set and the other is the non-relevant set.
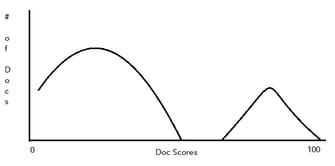
These workflows can be extremely useful for initial case assessments, compliance reviews, and internal investigations, where the end goal of the review is not to quickly find and produce every relevant document. Rather, the review in these types of cases is focused on gathering as much relevant information as possible or finding a story within the dataset. Thus, these types of reviews are generally more fluid and can change significantly as the review team finds more information within the data. New information found by the review team may lead to more data collections or a change in custodians, which can significantly change the dataset over time (something TAR 2.0 can handle but TAR 1.0 cannot). And because the machine provides updated scoring as the team investigates and codes more documents, it can even provide the team with new investigational avenues and leads. A TAR 2.0 workflow works well because it gives the review team the freedom to investigate and gain knowledge about a wide variety of issues within the documents, while still ultimately resulting in data reduction.
Conclusion
The above workflow examples illustrate that TAR does not have to be the rigid, complicated, and daunting workflow feared by many. Rather, TAR can be a highly adaptable and simple way to gain efficiency, improve end results, and certainly to reduce the volume of documents reviewed across a variety of use cases.
It is my hope that I have at least piqued your interest in the TAR 2.0 workflow enough that you’ll think about how it might be beneficial to you when the next document review project lands on your desk.
If you’re interested in discussing the topic further, please freely reach out to me at DBruno@lighthouseglobal.com.

About the Author




