

From Data to Decisions, AI is Improving Accuracy for eDiscovery
May 17, 2024
|
By:
You’ve heard the claims that AI can increase the accuracy of analytical tasks during eDiscovery. They’re true when the AI in question is being developed responsibly through proper scoping, iterative testing, and validation. As we have known for over a decade in legal tech circles, the computational power of AI (and machine learning in particular) is perfectly suited to the large data volumes at play for many matters and the types of classification assessments required for document review.
But how much of a difference can AI make? And what impact do large language models (LLMs) have in the equation beyond traditional approaches to machine learning? How do these boosts in accuracy help legal teams meet deadlines, preserve budget, and achieve other goals?

To answer these questions, we’ll look at several examples of privilege review from real-world matters. Priv is far from the only area where AI can make a difference, but for this article it’ll help to keep a tight focus. Also, we’ve been enhancing privilege review with AI since 2019, so when it comes to accuracy—we have plenty of proof.
What accuracy means for the two primary types of AI
Before we explore examples, let’s review the two relevant categories of AI and what they do in an eDiscovery context.
- Predictive AI leverages historical data to predict outcomes on new data. For eDiscovery, we leverage predictive AI to provide us with a metric on the likelihood a document falls under a certain classification (responsive, privileged, etc.) based on a previously coded training set of documents.
- Generative AI creates novel content based directly on input data. For eDiscovery, one example could be leveraging generative AI to develop summaries of documents of interest and answers to questions we may have about the facts present in these documents.
In today's context, both types of AI are built with LLMs, which learn from vast stores of information how to navigate the nuances and peculiarities of language as people actually write and speak it. (In a previous post, we share more information about LLMs and the two types of AI.)
Because each of these types of AI are focused on different goals and have different outputs, predictive and generative AI also have different definitions of accuracy.
- Accuracy for predictive AI is tied to a traditional sense of the truth: How well can the model predict what is true about a given document?
- Accuracy for generative AI is more fluid: A generative AI model is accurate when it faithfully meets the requirements of whatever prompt it was given. If you ask it to tell you what happened in a matter based on the facts at hand, it may make up facts in order to be accurate to the prompt. Whether the response is true or is based on the facts of the matter depends on the prompt, tuning mechanisms, and validation.
All that said, both types of AI have use cases that allow legal teams to measure their accuracy and impact.
Priv classifiers prove to be more accurate than search terms
Our first example comes from a quick-turn government investigation of a large healthcare company. For this matter, we worked with counsel to train an AI model to identify privilege and ran it in conjunction with privilege search terms.
The privilege terms came back with 250K potentially privileged documents, but the AI model found that more than half of them (145K) were unlikely to be privileged. Attorneys reviewed a sample of the disputed docs and agreed with the AI. That gave counsel the confidence they needed to remove all 145K from privilege review—and save their client significant time and money.
We saw similar results in another fast-paced matter. Search terms identified 90K potentially privileged documents. Outside counsel wanted to reduce that number to save time, and our AI privilege model did just that. Read the full story on AI and privilege review for details.
Let’s return to our definition of accuracy for predictive AI: How well did the model predict what was true about the documents? Very well and more accurately than search terms.
Now what about generative AI?
Generative AI can draft more accurate priv logs than people
We have begun to use generative AI to draft privilege log descriptions. That’s an area where defining accuracy is clear-cut: How well does the log explain why the doc is privileged?
During the pilot phase of our AI priv log work, we partnered with a law firm to answer that very question. With permission from their client, the firm took privilege logs from a real matter and sent the corresponding documents through our AI solution. Counsel then compared the log lines created by our AI model against the original logs from the matter.
They found that the AI log lines were 12% more accurate than those drafted by third party contract reviewers. They also judged the AI log lines to be more detailed and less repetitious.
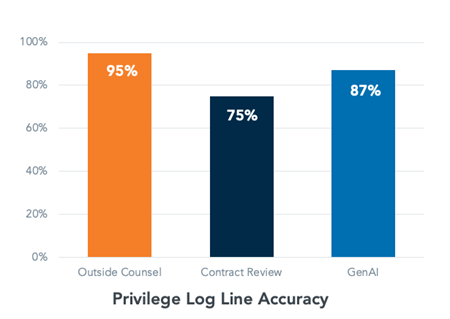
We have evidence from live matters as well. During one with a massive dataset and urgent timeline, outside counsel used our generative AI to create privilege logs and asked reviewers to QC them. During QC, half the log lines sailed through with zero edits, while the other half were adjusted only slightly. You can see what else AI achieved in the full case study about this matter.
More accurate review = more efficient review (with less risk)
Those accuracy numbers sound good—but what exactly do they mean for legal teams? What material benefits do you get from improving accuracy?
Several, including:
- Better use of attorney and reviewer time. With AI accurately identifying priv and non-priv documents, attorneys spend less time reviewing no-brainers and more time on documents that require more nuanced analysis. In cases where every document will be reviewed regardless, you can optimize review time (and costs) by sending highly unlikely docs to lower-cost contract resources and reserving your higher-priced review teams for close calls.
- Opportunities for culling. Attorneys can choose a cutoff at a recall that makes sense for the matter (including even 100%) and automatically remove all documents under that threshold from review and straight into production. This is a crisp, no-fuss way to avoid spending time and resources on documents highly unlikely to be privileged.
- Lower risk of inadvertently producing privileged documents. Pretty simple: The better your system is for classifying privilege, the less likely you are to let privileged info slip through review.
What does accuracy mean to you?
I hope this post helps clarify how exactly AI can improve accuracy during eDiscovery and what other benefits that can lead to.
Now it’s time to consider what all this means to you, your team, and your work. How important is accuracy to you? How do you measure it? Where would it help to improve accuracy, and what would you get out of that?
To help you think it through, we assembled a user-friendly guide that covers accuracy and six other dimensions of AI that change the way people think about eDiscovery today.
The guide includes brief definitions and examples, along with key questions like the ones above to help you craft an informed, personal point of view on AI’s potential.
Check it out below. And if you want to discuss accuracy and AI in depth with an expert—get in touch. That’s what we’re here for.
eBook Available Now
Find Your AI POV
How well does your team leverage AI to meet evolving industry demands? This guide is designed to help legal teams discover where they stand on major aspects and implications of using AI in eDiscovery.


About the Author




